
Fuel虚拟机
亮点:
- FuelVM构成了Fuel平台的心脏,它汲取了EVM和Solana的SVM等不同虚拟机设计的精髓。
- FuelVM致力于开发尽可能减少状态维护的应用,通过引入原生资产、短暂脚本和短暂支出条件等功能,从而促进更加去中心化且易于接入的架构。
- UTXO模型实现了并行交易执行,即同时处理多个非冲突交易,进而提高吞吐量并减少延迟。
- FuelVM是一款基于寄存器的虚拟机,相比传统堆栈式设计提供了更出色的性能,并提供了一套有组织的指令集以高效运行。谓词、脚本和合约是FuelVM的重要组成部分,使灵活的支出条件、交易处理和状态管理成为可能。
FuelVM是整个Fuel平台的核心所在;其设计融合了多年来从其他虚拟机(如EVM、Solana的SVM等)设计中积累的经验。
FuelVM让开发者能够摆脱依赖于智能合约的有状态应用设计模式,转而采用更多功能丰富且状态最小化的设施,如原生资产、短暂脚本和短暂支出条件。通过为开发者提供构建状态最小化应用的新途径,我们不仅提升了全节点的可持续性,同时也确保了架构的去中心化和易用性,这与以太坊的核心价值观相契合。
下文中,我们将深入探讨FuelVM的各项关键特性。
UTXO模型以及并行计算
Fuel的并行交易执行模型是支撑其效率和可扩展性的关键。相较于传统的顺序处理方法,这种模型显著提升了吞吐量并降低了延迟。该模型将大型任务分解为更小的子任务,以便在多个处理单元上同时执行,从而实现高效的资源利用。
并行化依赖于访问列表和UTXO(未花费交易输出)模型作为基础,两者协同工作,使非冲突交易的并发处理成为可能。
我们的技术利用UTXO模型在Fuel上执行交易,基于UTXO建模的交易可以处理从简单的代币转移至复杂的智能合约调用等各种操作。
Fuel上的地址持有未花费的货币单位,可在FuelVM中进行消费和交易。
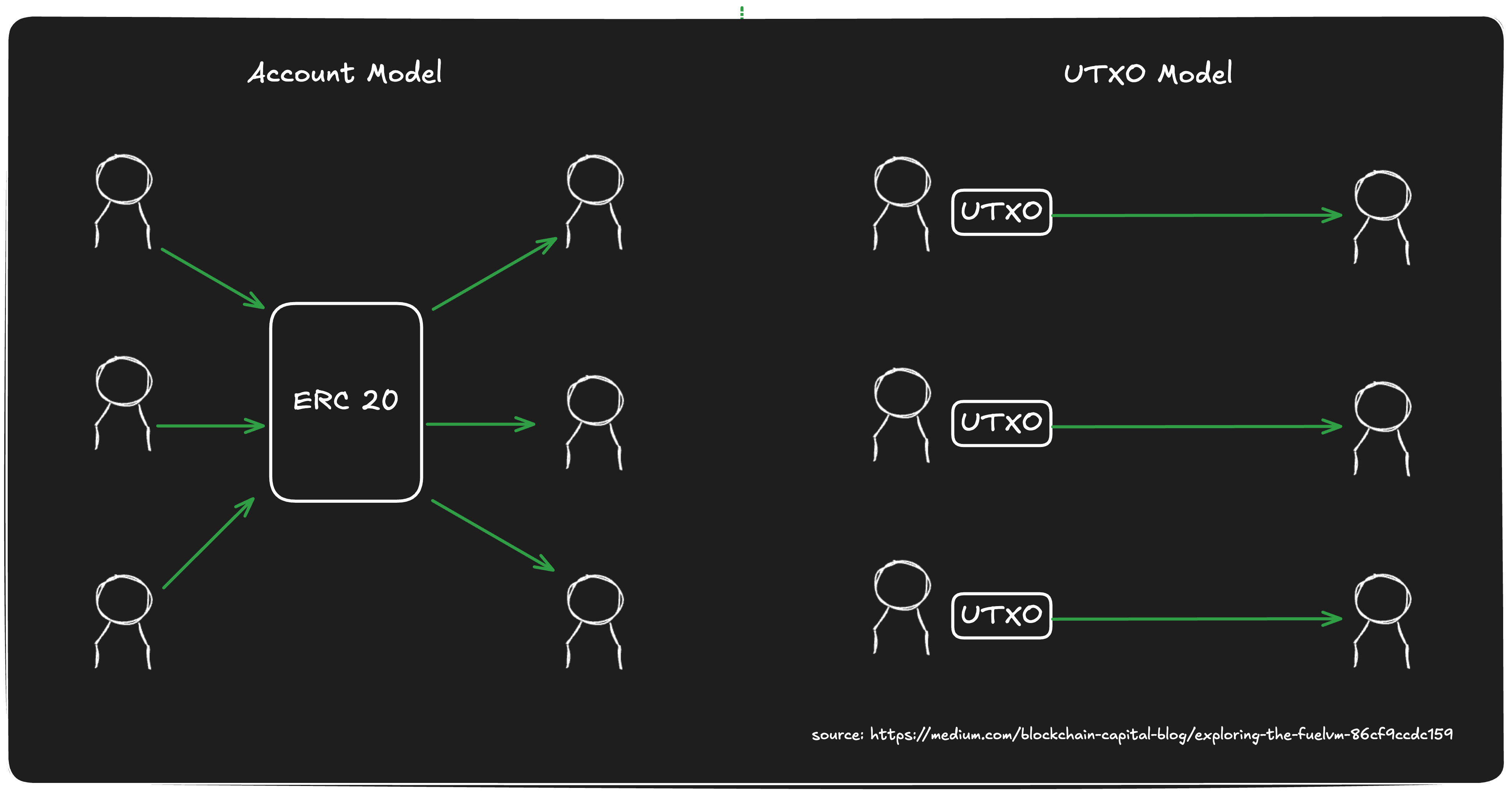
借助UTXO模型,可以有效地实现交易的并行处理。在实际操作中,用户需要为每笔交易指定相应的输入和输出。当交易之间不存在相互影响时,这些交易就可以并行处理,这使得Fuel能够随着每台机器的核心数量增加而水平扩展。
以寄存器为基础的设计
FuelVM作为一款基于寄存器的虚拟机运作,而EVM及其他多数虚拟机则采用基于堆栈的架构。
基于寄存器的虚拟机性能始终优于基于堆栈的虚拟机。
FuelVM配备了64个寄存器,每个8字节大小,其中16个被预留,支持6位寻址。
| value | register | name | description |
|---|---|---|---|
| 0x00 | $zero | zero | Contains zero (0), for convenience. |
| 0x01 | $one | one | Contains one (1), for convenience. |
| 0x02 | $of | overflow | Contains overflow/underflow of addition, subtraction, and multiplication. |
| 0x03 | $pc | program counter | The program counter. Memory address of the current instruction. |
| 0x04 | $ssp | stack start pointer | Memory address of bottom of current writable stack area. |
| 0x05 | $sp | stack pointer | Memory address on top of current writable stack area (points to free memory). |
| 0x06 | $fp | frame pointer | Memory address of beginning of current call frame. |
| 0x07 | $hp | heap pointer | Memory address below the current bottom of the heap (points to used/OOB memory). |
| 0x08 | $err | error | Error codes for particular operations. |
| 0x09 | $ggas | global gas | Remaining gas globally. |
| 0x0A | $cgas | context gas | Remaining gas in the context. |
| 0x0B | $bal | balance | Received balance for this context. |
| 0x0C | $is | instructions start | Pointer to the start of the currently-executing code. |
| 0x0D | $ret | return value | Return value or pointer. |
| 0x0E | $retl | return length | Return value length in bytes. |
| 0x0F | $flag | flags | Flags register. |
FuelVM指令集
FuelVM的每条指令占据4字节的空间,并具有以下结构:
- 操作码:8位
- 寄存器标识符:6位
- 立即数:依据具体操作的不同,长度可以是12位、18位或24位。
FuelVM的指令集详见此处的文档。
https://docs.fuel.network/docs/specs/fuel-vm/instruction-setIcon Link.
内存
FuelVM采用按字节索引的内存布局,其大小可通过VM_MAX_RAM参数来配置。因此,每个FuelVM实例都可以自行决定为虚拟机分配的内存容量。
内存管理采用了栈和堆的模型。栈从初始化后的虚拟机数据和调用上下文中的调用帧后面开始,位于左侧;而堆则始于由VM_MAX_RAM参数指定的字节地址。
每次在栈上分配一个字节都会使栈索引增加1,而在堆上分配一个字节则会使可写索引减少1。因此,栈是向上扩展的,而堆则是向下扩展的。
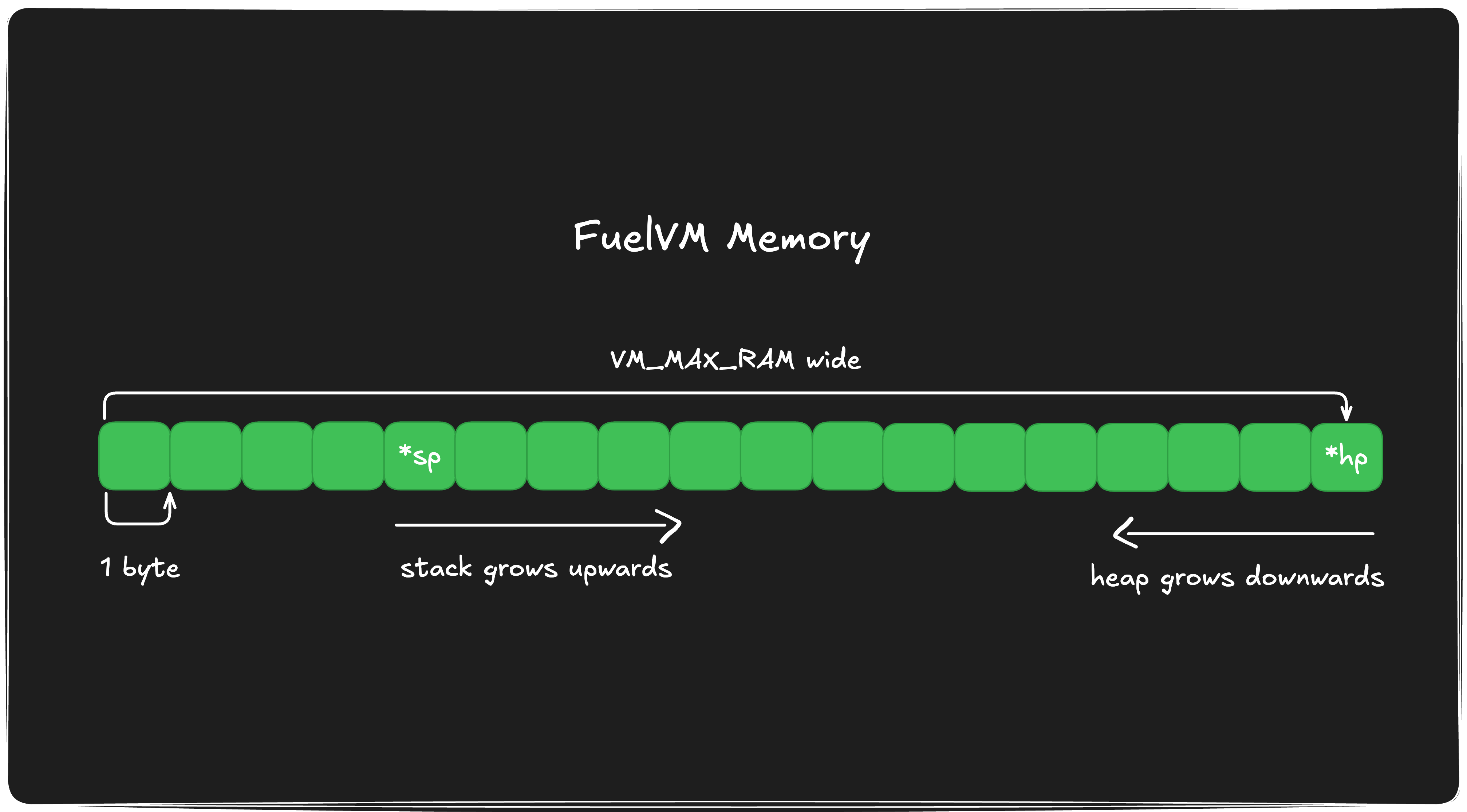
栈和堆有以下重要寄存器:
$ssp(0x05): 当前可写栈区底部的内存地址。$sp(0x06): 当前可写栈区顶部的内存地址(指向空闲内存)。$hp(0x07): 当前堆底下的内存地址(指向已用或越界的内存)。
FuelVM实施所有权检查,确保各上下文仅能访问其所属的内存区域。关于这一主题的更多细节将在后续章节中展开讨论。
谓词、脚本与合约
要深入了解Fuel,需掌握以下几个关键概念:
- 谓词(Predicates)
- 脚本(Scripts)
- 合约(Contracts)
让我们再深入一点。
谓词(Predicates)
谓词是用于设定原生资产支出条件的无状态程序。当FuelVM执行编译后的字节码,并依据其返回的布尔值(真或假)来判断资产是否可以在交易中被花费。如果返回值为真,则资产可以被花费;若为假,则交易将被视为无效。
用户可以编程设置各种复杂的支出条件,例如要求五人中有三人同意才能进行交易,或者交易必须包含特定的输入和输出(即意图)。
谓词操作无状态,没有持久存储,不能调用其他智能合约。
脚本(Scripts)
脚本作为Fuel交易的起点,决定了交易的执行流程。与谓词类似,脚本也不具备持久化存储的能力。不过,它们能够调用作为Fuel交易一部分的合约输入,而这些输入可以拥有自己的持久化存储空间。这使得Fuel能够原生支持诸如多调用和条件执行等高级特性。
智能合约(Contracts)
Fuel在其UTXO模型中引入了对智能合约的支持。智能合约是有状态的实体,可以被其他合约调用。Fuel中的智能合约通过InputContract类型表示。要了解更多信息,请参考 Input Contract section。
首次在一个交易中调用合约是通过脚本进行的,随后合约可以进一步调用其他合约。
合约拥有持久化存储,采用了32字节的键和32字节的值组成的键值对形式。团队正在探索多种数据结构,以找到提交合约存储的最佳方案。
上下文(Contexts)
上下文是Fuel用来隔离不同执行环境的方法,适用于谓词估计和验证、脚本执行和合约调用等场景。每个上下文都拥有独立的内存所有权。
Fuel定义了四种类型的上下文:
- 谓词估计
- 谓词验证
- 脚本执行
- 调用。
其中,前三种被称为外部上下文,因为它们的帧指针$fp值为零;而调用则被称为内部上下文,因为其帧指针$fp值为零。
谓词gas预估
Fuel交易会为每个谓词指定一个predicateGasUsed值,用于预估执行该谓词所需的gas消耗量。在验证过程中,若实际消耗的燃气量超过了预估的predicateGasUsed,则该交易会被取消,所有更改将被撤销。

用户可以选择在本地执行预测性估算,或是向远程全节点发起请求,由其在FuelVM中执行谓词并报告消耗的燃气量。此过程旨在准确评估执行谓词所需的资源。
值得注意的是,谓词估计上下文不允许进行持久化存储操作或调用智能合约,以确保估算过程的独立性和安全性。
谓词验证
在执行交易脚本前,必须先通过FuelVM在谓词验证上下文中确认所有谓词部分均返回真。FuelVM会在谓词验证上下文中验证交易的谓词,以确保它们满足条件。

谓词验证上下文不允许进行持久化存储操作或调用智能合约,以保证其无状态性和安全性。
脚本执行
在所有谓词验证成功后,进入脚本执行阶段。脚本执行上下文虽然不允许持久化存储,但它能够调用智能合约,从而实现更复杂的交易逻辑。这一设计既保留了必要的限制,又赋予了脚本执行更多的灵活性。

函数调用
调用上下文负责执行合约,提供灵活的数据处理能力,支持持久化存储和合约间的相互调用。调用上下文可以通过以下两种方式之一创建:
- 脚本调用智能合约
- 合约调用另一个合约输入

每次调用都会创建一个“调用帧”,该帧被压入栈中,并包含有助于FuelVM执行调用上下文的元数据。调用上下文不能改变调用者的状态,只能访问自己的栈和堆,这保证了调用的安全性和隔离性。
| bytes | type | value | description |
|---|---|---|---|
| Unwritable area begins. | |||
| 32 | byte[32] | to | Contract ID for this call. |
| 32 | byte[32] | asset_id | asset ID of forwarded coins. |
| 8*64 | byte[8][64] | regs | Saved registers from previous context. |
| 8 | uint64 | codesize | Code size in bytes, padded to the next word boundary. |
| 8 | byte[8] | param1 | First parameter. |
| 8 | byte[8] | param2 | Second parameter. |
| 1* | byte[] | code | Zero-padded to 8-byte alignment, but individual instructions are not aligned. |
| Unwritable area ends. | |||
| * | Call frame's stack. |
当调用上下文成功结束后,其调用帧将从栈中弹出,但在执行期间在堆上分配的空间仍然会保留在内存中,以便后续可能的访问。
调用上下文通过$ret和$retl寄存器返回结果。对于较大尺寸的返回值,可以先将其写入堆中,之后由调用者上下文读取,从而确保了大容量数据的有效传递。
内存策略
在了解了FuelVM的各种执行上下文后,我们现在探讨这些上下文中读取和写入内存所遵循的策略。
上下文读取策略
上下文可以从索引0(也就是内存地址的起始点)到历史上最高的$sp,以及从当前的$hp到VM_MAX_RAM(也就是内存地址的终止点)之间的栈范围内读取数据。
如果尝试从历史上最高的$sp与当前的$hp之间的区域读取数据,系统将抛出错误。
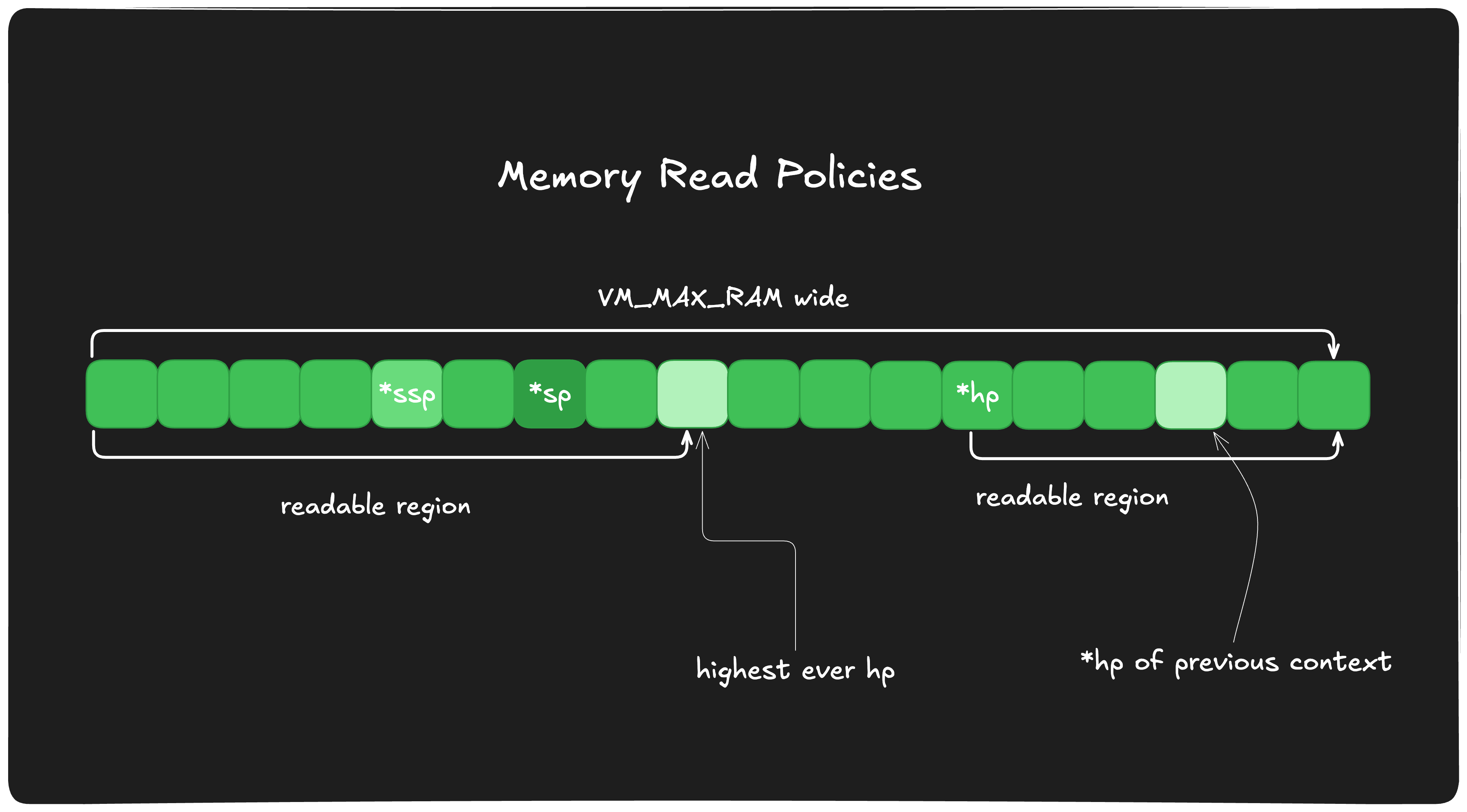
那么,“历史上最高的$sp”具体指的是什么呢?
由于栈的大小可以动态调整,在某些上下文执行过程中,$sp可能曾经到达过例如索引1000的位置,但随后元素被弹出栈,使得当前的$sp变为900。在这种情况下,该调用上下文执行期间历史上最高的$sp是1000,因此直到1000的内存区域对于栈来说是可读的。
上下文写入策略
给定的上下文可以在其$ssp和当前$hp之间的任何区域内写入数据;因此,该内存区域可以被分配并用于写入数据。
在向此内存区域写入数据之前,需要首先分配相应的字节数。对于栈,这通过CFE和CFEI操作码完成;而对于堆,则通过ALOC操作码实现。
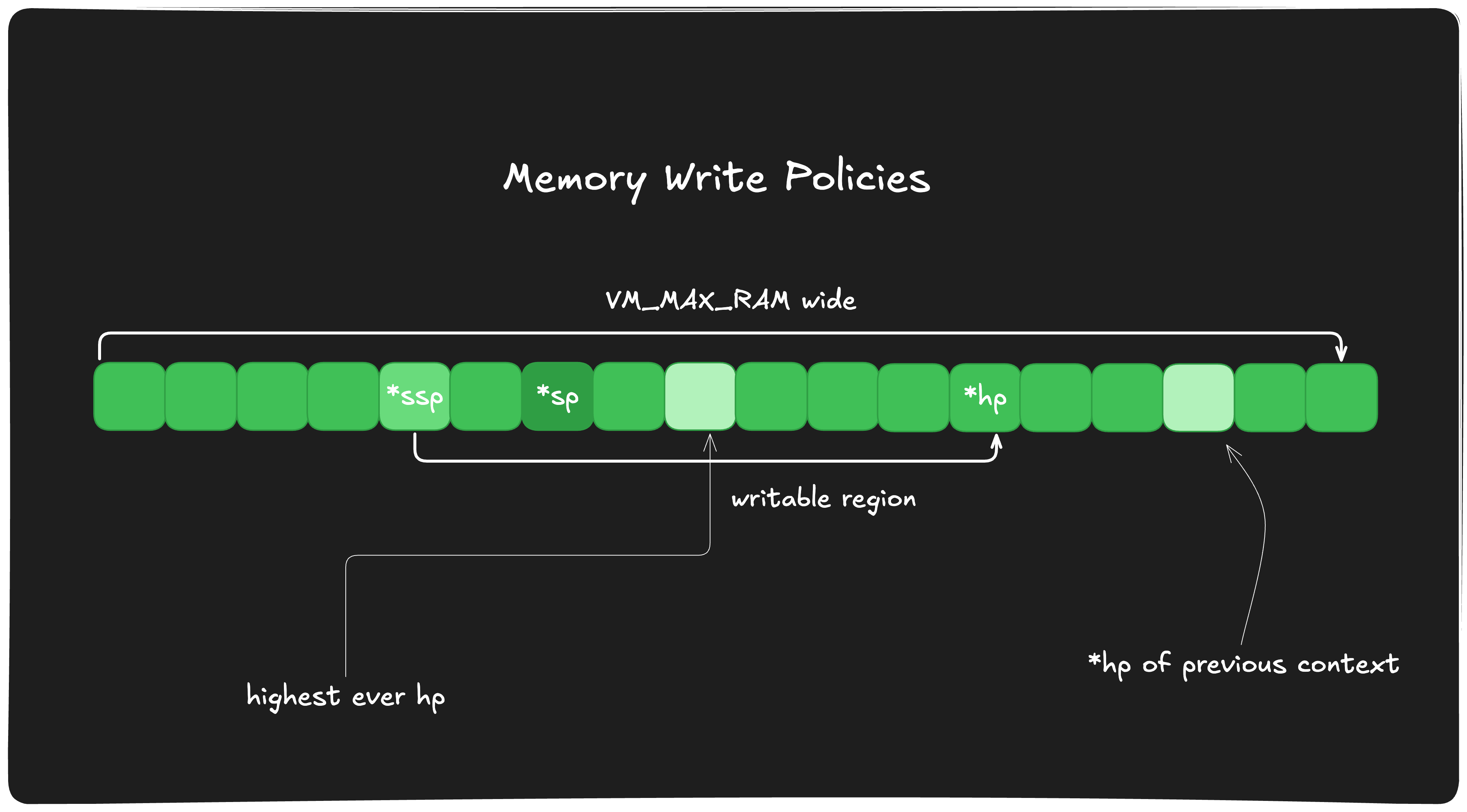
请注意,一旦上下文完成,栈上的所有值(包括调用帧和执行期间栈上分配的所有值)都将被清除。然而,堆分配的数据会保留,后续上下文只能在其$hp之下写入数据。这意味着,尽管上下文结束时栈上的信息会被清除,堆上的数据仍然保留在内存中,以供后续操作使用。
虚拟机初始化和配置
虚拟机配置
虚拟机可以由以下参数进行配置
| name | type | value | note |
|---|---|---|---|
| CONTRACT_MAX_SIZE | uint64 | Maximum contract size, in bytes. | |
| VM_MAX_RAM | uint64 | 2**26 | 64 MiB. |
| MESSAGE_MAX_DATA_SIZE | uint64 | Maximum size of message data, in bytes. |
虚拟机初始化
本节概述了每次运行虚拟机时的初始化过程。为了初始化虚拟机,按照以下顺序依次将数据压入栈中:
- 交易哈希:一个32字节、按字对齐的值,用于唯一标识交易,其计算方法详见官方文档。
- 基础资产ID:同样是一个32字节、按字对齐的值,用来标识交易中涉及的基础资产类型。
- 最大输入数量(
MAX_INPUTS)对。每一对包含一个32字节的资产ID和一个64位无符号整数表示的余额。这些对的具体内容取决于上下文:- 对于谓词估计和验证,这些对的值被设置为零,因为这些阶段不需要实际的余额信息。
- 对于脚本执行,则按照交易输入中出现的资产ID的自由余额,按升序排序;若提供的资产ID数量不足
MAX_INPUTS,则不足的部分将以零值填充。
- 交易长度:以字节为单位,64位无符号整数,表示整个交易序列化后的大小,按字对齐。
- 序列化的交易:整个交易的数据被编码成连续的字节数组形式。
然后初始化以下寄存器(所有未明确初始化的寄存器默认初始化为零):
$ssp:指向可写栈区的起始位置,该位置紧跟在序列化交易之后,计算公式为32 + 32 + MAX_INPUTS*(32+8) + size(tx)。$sp:初始时等于$ssp,意味着可写栈区开始时为空。$hp:初始值为VM_MAX_RAM,表示堆区从内存顶部开始,开始时为空。